Дискретная математика:
логика, группы, графы, фракталыАкимов О.Е.
2.4. Алгебраические системы на базе групп
Кодовое расстояние и помехозащищенность
Помехозащищенность кода можно выяснить на основе известного кодового расстояния. Кодовое расстояние между словами a и b определяется как число несовпадающих символов в этих словах, например: a = 10110, b = 11011, здесь расстояние равно d(a, b) = 3. Корректирующий код способен исправлять любые комбинации из m и меньшего числа ошибок, если его минимальное кодовое расстояние удовлетворяет условию: dmin ≥ 2m + 1. Для иллюстрации этого неравенства приведем следующий пример.
Возьмем три рядом стоящих слова (термин «рядом стоящие» означает, что между этими словами других слов быть не может):
a = 0100, b = 0110, c = 0010.
Для получения соответствующих кодовых слов, их нужно умножить на порождающую матрицу, которую мы возьмем из предыдущего примера G' :
fa = 1110100, fb = 0010110, fc = 1100010.
Кодовые расстояния между этими словами равны:
d(fa , fb) = 3, d(fb , fc) = 4, d(fa, fc) = 3.
Предположим, что при передачи информации в канале связи произошел сбой и второе кодовое слово изменилось на fb' = 0110110. Тогда по минимальному кодовому расстоянию мы все же сможем определить, что из трех возможных слов передавалось скорее всего слово fb, так как:
d(fa , fb') = 2, d(fb , fb') = 1, d(fc , fb') = 3.
Если же были допущены две ошибки, например, в пятом и четвертом разрядах, то становится непонятным, какое из кодовых слов — fb или fc — на самом деле передавалось, так как fb'' = 0111110,
d(fa , fb'') = 3, d(fb , fb'' ) = 2, d(fc , fb'' ) = 2.
Отсюда, чем больше минимальное кодовое расстояние между словами, тем лучше защищен код от помех. По вышеприведенному неравенству можно установить, что при dmin = 3 число обнаруженных и исправленных ошибок не может быть больше одной (m ≤ 1), поскольку m ≤ (dmin – 1)/2.
К сказанному добавим, что все коды ошибок, представленные в табл. 2.87, можно было бы установить и по проверочной матрице H'. С этой целью каждое кодовое слово необходимо было бы умножать на транспонированную матрицу H': s = f (H ' )*. Все рассуждения мы проводим на матрицах, записанных именно в систематической форме. Если брать ленточные матрицы, то информационные и проверочные символы в кодовых словах окажутся перемешанными, что вызывает определенные неудобства при декодировании.
Для закрепления последнего материала исследуем помехозащищенность нетривиального кода с
n = 15 и g(x) = 1 + x4 + x6 + x7.
Делением x15 + 1 на g(x) находим проверочный многочлен:
h(x) = x8 + x7 + x6 + x4 + 1.
Порождающая и проверочная матрицы в ленточной форме:
G =
,
H =
.
Методом остаточного многочлена находим эти же матрицы, но записанные уже в систематической форме:
G' =
,
H' =
.
Комбинируя столбцы исходных ленточных матриц, мы можем лишний раз убедиться в правильности нахождения этих матриц.
Проверочные соотношения равны:
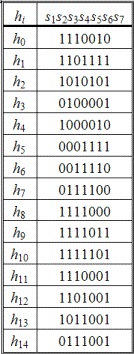
Все коды ошибок представлены в табл. 2.88.
Таблица 2.88
Помехозащищенность исследуем на трех кодовых словах:
a = 00110011, b = 10110011, c = 10010011,
которые дают следующие защищенные последовательности:
fa = 101000000110011,
fb = 001010110110011,
fc = 110001110010011.
Расстояния между словами:
d(fa , fb) = 4, d(fb , fc) = 6, d(fa, fc) = 6.
Так как m ≤ (dmin – 1)/2 =3/2, данный код может обнаружить и исправить не более одной ошибки. Действительно, если в 10 и 14 разрядах одновременно произойдет сбой, т.е.
f'b'' = 101000110110011,
появятся два одинаковых расстояния:
d(fa , fb'' ) = 2, d(fb , fb'' ) = 2, d(fc , fb'' ) = 4.
и мы не сможем определить истинное слово.
Для задания произвольного кода нужно указать полный список кодовых слов. Например, следующий список слов имеет довольно приличную (для своего значения n = 11) степень защищенности:
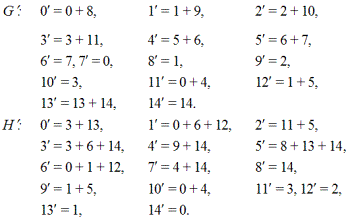
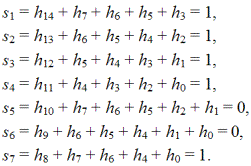


|
|